Подготовка набора данных ParalWiki¶
В наборе данных ParalWiki используются русско-английские выровненные статьи Википедии (дамп Википедии от декабря 2021 г.). Были исключены все статьи, заголовок которых начинается со слов «Список», «List of», размер которых менее 800 символов, а количество предложений меньше 20. Затем все оставшиеся пары статей были разделены на 2 группы по 5 корзин (bins) в каждой в зависимости от размера статей на русском языке. Статистика набора данных представлена в таблицах 1 и 2 ниже.
Таблица 1 Статистика сопоставимых по размеру статей
Размер в предложениях на русском языке |
Количество |
Средний размер текстов на русском языке |
Средний размер текстов на английском языке |
|---|---|---|---|
(9, 50] |
67549 |
2577.48 |
2654.86 |
(50, 100] |
29981 |
5756.1 |
5887.58 |
(100, 200] |
10791 |
12559.59 |
12842.3 |
(200, 400] |
3593 |
26356.38 |
26756.85 |
(400, 1000] |
973 |
53309.99 |
53472.66 |
Таблица 2 Статистика несопоставимых по размеру статей
Размер в предложениях на русском языке |
Количество |
Средний размер текстов на русском языке |
Средний размер текстов на английском языке |
|---|---|---|---|
(9, 50] |
143519 |
2334.8 |
10571.68 |
(50, 100] |
56188 |
5626.9 |
15275.5 |
(100, 200] |
24073 |
12160.07 |
19376.16 |
(200, 400] |
8132 |
24831.26 |
21282.89 |
(400, 1000] |
2308 |
56628.01 |
19605.9 |
Далее было отобрано по 500 документов из сопоставимых и несопоставимых статей всех подгрупп. Это дает набор данных, содержащий 1000 пар документов, который определяет тестовую выборку. Также была создана дополнительная тестовая выборка, включающая статьи из набора данных GWikiMatch. Из оставшихся статей были образованы обучающая и валидационная выборки. Итоговая статистика по набору данных приведена в таблице 3.
Таблица 3 Статистика для набора данных ParalWiki
Т естовая |
Дополнительная тестовая |
Валидационная |
Обучающая |
|
|---|---|---|---|---|
Кол-во пар документов |
1000 |
2193 |
15000 |
503758 |
Уникальное кол-во докумен тов-запросов |
1000 |
2193 |
15000 |
503472 |
Cредний размер документа в предложениях на русском языке |
197.42 |
143.54 |
58.84 |
57.73 |
Cредний размер документа в предложениях на английском языке |
161.47 |
187.76 |
87.39 |
86.7 |
Cредний размер документа в символах на русском языке |
20532.6 |
14555.25 |
5288.3 |
5186 |
Cредний размер документа в символах на английском языке |
1 7867.47 |
20973.96 |
8774.71 |
8728.77 |
Среднее кол-во позитивных примеров на 1 документ |
1 |
1 |
1 |
1 |
Среднее кол-во негативных примеров на 1 документ |
0 |
0 |
0 |
0 |
SimEnWiki, SimRuWiki¶
Наборы данных SimRuWiki, SimEnWiki были получены путем выбора близких по входящим и исходящим ссылкам документов (рисунок 1). Для этого использовался алгоритм Милне-Виттена.
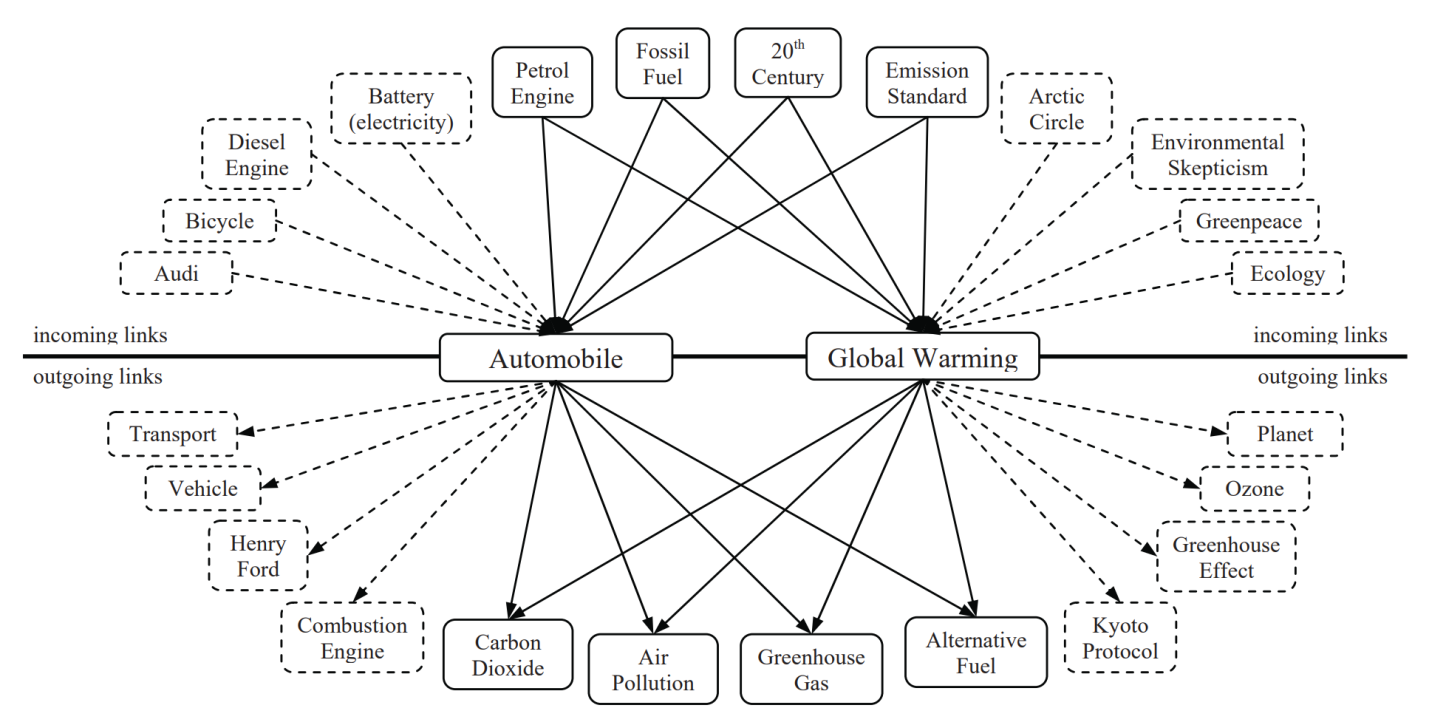
Рисунок 1 Пример входящих исходящих ссылок для статей про автомобиль и глобальное потепление
Первая мера определяется углом между векторами ссылок, найденных в двух интересующих статьях. Они почти идентичны векторам TF × IDF, широко используемым при поиске информации. Единственное отличие состоит в том, что мы используем количество ссылок, взвешенное по вероятности появления каждой ссылки, а не количество терминов, взвешенное по вероятности появления термина. Эта вероятность определяется общим количеством ссылок на целевую статью над общим количеством статей. Таким образом, если s и t являются исходной и целевой статьями, то вес w ссылки \(s\overset{\rightarrow}{}t\) определяется формулой:
\(w\left( s\overset{\rightarrow}{}t\right) = \log_{10}\left ( \frac{|W| - |T| + 0.5}{|T| + 0.5} \right), если s \in T, иначе 0\)
где T — набор всех статей, ссылающихся на t, а W — набор всех статей в Википедии. Другими словами, вес ссылки — это обратная вероятность любой ссылки на цель или 0, если ссылка не существует. Таким образом, ссылки считаются менее важными для оценки сходства между статьями, если многие другие статьи также ссылаются на ту же статью. Тот факт, что обе статьи ссылаются на статью про науку, имеет гораздо меньшее значение, чем если бы они обе ссылались на конкретную тему, такую как термодинамика атмосферы.
Эти веса ссылок используются для создания векторов для описания каждой из двух интересующих статей. Сходство статей определяется по взвешенному сходству Жаккара.
Вторая мера, которая была использована, смоделирована по образцу нормализованного расстояния Google, который основан на встречаемости терминов на веб-страницах. Название происходит от использования поисковой системы Google для получения страниц, на которых упоминаются интересующие термины. Страницы, содержащие оба термина, указывают на родство, а страницы, содержащие только один из терминов, говорят об обратном. В итоге для каждой пары статей были сохранены следующие значения: :math:`` - сходство по входящим, \(out\) - по исходящим, \(rating = \left( \frac{+ out}{2} \right)\). Для выбора позитивных/негативных примеров были подобраны специальные пороги. Мы считаем пару документов похожими, если меры сходства удовлетворяют следующим критериям \(> 0.82\) и \(out > 0\). Такие пары документов считаются позитивными примерами. Пары документов, для которых выполняются условия \(0.25 < rating < 0.35\) и \(> 0\) считаются трудными негативными примерами. Идея заключается в том, чтобы в качестве негативных примеров использовать что-то отдалено близкое, а не статьи по совершенно другой тематике. Общая статистика по набору данных представлена в таблице 4.
Таблица 4. Общая статистика по набору данных
Общее количество позитивных пар |
Общее количество негативных пар |
Уникальное количество статей c хотя бы одной позитивной парой |
Уникальное количество статей c хотя бы одной негативной парой |
|
|---|---|---|---|---|
SimRuWiki |
17757971 |
10049161 |
789827 |
717352 |
SimEnWiki |
103097966 |
35060994 |
3363203 |
2559847 |
Эти данные были очищены от статей без позитивных примеров, пустых статей и статей, состоящих из пустых строк, статей с менее, чем 5 предложениями, дублей. Негативные пары были сохранены по 5 штук для одной статьи. Далее, с помощью равномерного распределения были созданы тестовая, валидационная и обучающая выборки данных. Итоговая статистика по набору данных приведена в таблицах 5,6.
Таблица 5 Статистика для набора данных SimEnWiki
Тестовая |
Валидационная |
Обучающая |
|
|---|---|---|---|
Кол-во пар документов |
681494 |
1436451 |
31831339 |
Уникальное кол-во до кументов-запросов |
45000 |
95000 |
2095733 |
Cредний размер документа-запроса в предложениях |
47.9 |
47.85 |
47.48 |
Cредний размер до кумента-кандидата в предложениях |
64.54 |
63.22 |
53.73 |
Cредний размер документа-запроса в символах |
4401.08 |
4446.56 |
4389.41 |
Средний размер до кумента-кандидата в символах |
6171.93 |
6054.43 |
5060.52 |
Среднее кол-во позитивных примеров на 1 документ |
13.15 |
13.13 |
13.22 |
Среднее кол-во негативных примеров на 1 документ |
4.98 |
4.98 |
4.95 |
Таблица 6 Статистика для набора данных SimRuWiki
Тестовая |
Валидационная |
Обучающая |
|
|---|---|---|---|
Кол-во пар документов |
219124 |
504955 |
6389197 |
Уникальное кол-во левых документов |
15000 |
35000 |
442906 |
Cредний размер документа-запроса в предложениях |
44.57 |
45.03 |
44.65 |
Cредний размер до кумента-кандидата в предложениях |
55.62 |
55.36 |
51.35 |
Cредний размер документа-запроса в символах |
3840.49 |
3908.56 |
3861.57 |
Средний размер до кумента-кандидата в символах |
5024.62 |
4998.94 |
4537.55 |
Среднее кол-во позитивных примеров на 1 документ |
12.57 |
12.42 |
12.41 |
Среднее кол-во негативных примеров на 1 документ |
4.97 |
4.97 |
4.95 |